implement custom optimizer with Optax
Optax is an optimization library for JAX which provides out-of-the-box apis for commonly used ml loss functions, optimizers and utilities like learning rate schedulers.
In general, defining your own optimizers with Optax is quite simple. Use the optax.chain api to combine different transforms. Transforms are pure functions that act on model parameters to update their values according to the update rules defined within the transform function. They are available as ''optax.transform_foo''. One can simply think of them as chunks of math operations that take input x, perform some computation on it and return the transformed result. For example, if you want to define a new optimizer which follows the update rule [adam -> clip gradients by 0.8 -> apply learning rate of 0.02 ] the code would look like this -
transform1 = optax.scale_by_adam()
transform2 = optax.clip(0.8)
transform3 = optax.scale_by_learning_rate(0.02)
chained_transform = optax.chain(transform1, transform2, transform3)
This chained_transform is now a complete optimizer and can be used to update the parameters of a model (similar to how one would call optax.adam() ).
However, there might be times when we need to construct an optimizer whose update rules are not defined as per the available transform functions here. For example, if you are trying to implement the Muon optimizer, the update steps look something like this

(taken from Keller Jordan's blog)
where the NewtonSchulz5 operation is not available as a transform function in Optax(yet). This is where this blog comes in as a general guide to implement custom optimizers with Optax that require mathematical transforms which are not part of the core library.
Looking into the Optax Optimizer
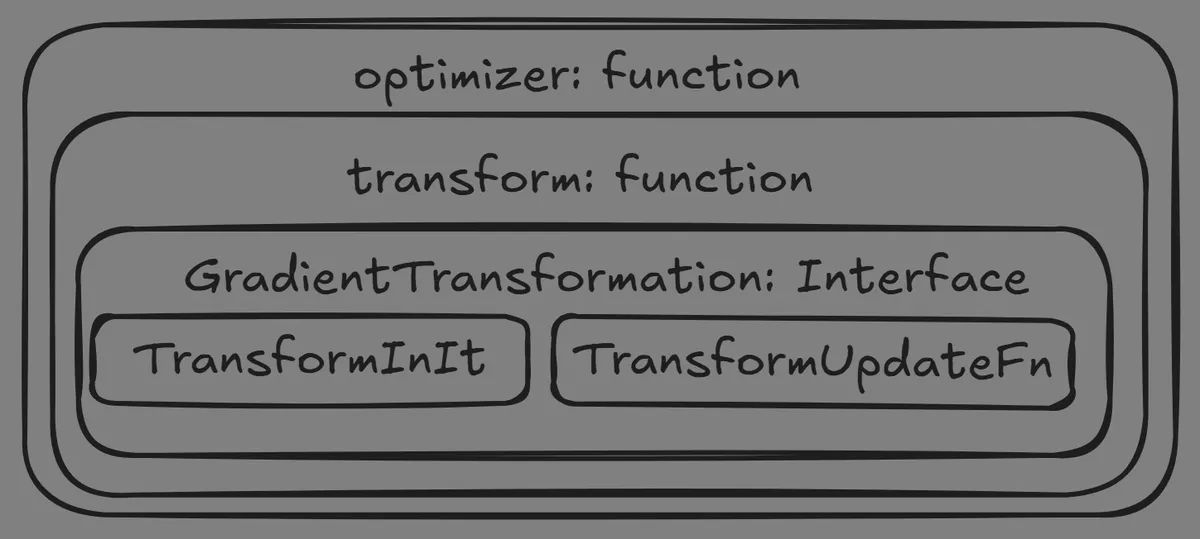
At its core, Optax functionality is built around its base module which consists of all interfaces and datatypes required by the library. The interface we care about here is called GradientTransformation, which has the following signature
class GradientTransformation(NamedTuple):
init: TransformInitFn
update: TransformUpdateFn
TransformInitFn is a callable responsible for setting up the initial parameters, while TransformUpdateFn is a callable that applies the update rules. All the parameters passed here are treated as instances of Pytree.
The former is invoked internally when you initialize the optimizer as
solver = optax.adam(lr)
state = solver.init(params)
and returns the initial state of the optimizer that has the same Pytree structure as the parameters. The latter is for when you want to update the parameters as
updates, state = solver.update(updates, state)
Implementing the custom transform
With this in mind, we can now define our own transform by writing a function that returns a GradientTransformation object
class CustomOptState(NamedTuple):
evolving_state: base.Updates
def scale_by_custom_optimizer(constant:float)-> GradientTransformation:
def matrix_ops(X:jax.Array)-> jax.Array:
# perform custom matrix operations
return X
def init_fn(params):
# initialize the state of the optimizer as initial_state
return CustomOptState(evolving_state=initial_state)
def update_fn(updates, state, params: Optional[base.Params]):
# update the new state
# apply the matrix_ops
# optional can do other parameter updates like weight decay
return updates, CustomOptState(evolving_state=updated_state), params
return GradientTransformation(init_fn, update_fn)
Since JAX functions are pure functions, optimizers themselves are stateless and we need a way to keep track of the evolving states of the optimizers. This is where the CustomOptState comes in. It is defined as a NamedTuple and its structure can be any Pytree. In most cases this will mirror the nested structure of the model's parameters to store per-parameter state.
We can then define our transform that should implement two functions called init_fn and update_fn. Along with this, it might contain any other custom matrix operations functions that we need to perform.
The init_fn function is passed a Pytree object that will match the shape of the params to be updated and returns the initial state of the optimizer as a CustomOptState object. In most cases, the passed argument is the model parameters dict.
def init_fn(params):
# initialize the state of the optimizer as all zeros
initial_state = jax.tree.map(jnp.zeros_like,params)
return CustomOptState(evolving_state=initial_state)
The update_fn is where you pass your new values(eg the gradients) and the current state(ie the running state of the optimizer as a CustomOptState object) and return the parameter update values and the CustomOptState object with the updated state. Optionally you can also pass the model parameters in order to do weight decay or other updates.
def update_fn(grads: base.Updates, state: CustomOptState):
# simple update rules for example
# calculate the new momentum/running average
updated_state = jax.tree.map(
lambda s, g: constant * s + g, state.evolving_state, grads)
# calculate the custom optimization step
update = matrix_ops(updated_state)
return update, CustomOptState(evolving_state=updated_state)
The final step is to return the GradientTransformation object with these two functions.
return GradientTransformation(init_fn, update_fn)
We have our custom transform ready, only step now left is to use it to to define the optimizer that will call on this transform.
def custom_optimizer(lr: float,constant:float) -> base.GradientTransformation:
return optax.chain(
scale_by_custom_optimizer(constant),
transform.scale_by_learning_rate(lr)
)
The scale_by_learning_rate is just -( update * lr ). The lr ideally should be annotated as base.ScalarOrSchedule, since it can be a float value or a scheduler.
And we have our new optimzer ready.
solver = custom_optimizer(lr,constant)
state = solver.init(params)
updates, state = solver.update(grads, state)
At this point, updates can be applied to parameters using optax.apply_updates.
References
[1] Optax documentation - https://optax.readthedocs.io/en/latest/api/combining_optimizers.html
[2] Muon optimizer - https://kellerjordan.github.io/posts/muon/
[3] Code - github